How do I control the way the PDF index is generated?
For example:
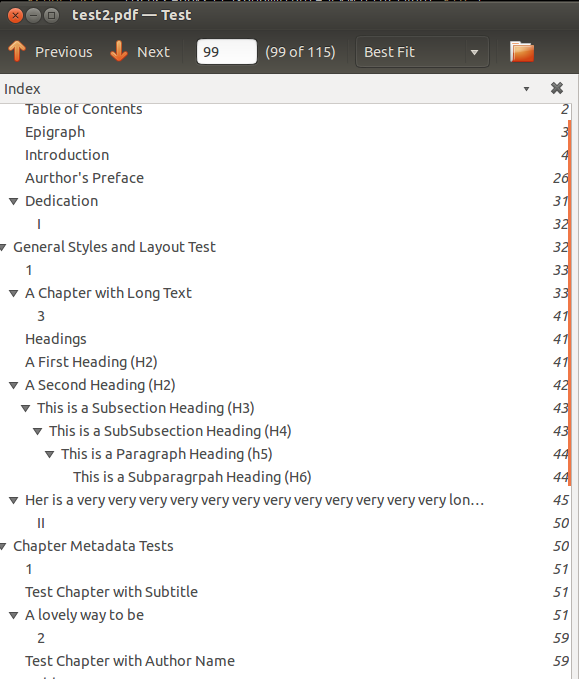
The above index is, as far as I can tell, generated from <H1><H2><H3><...> tags.
The issue is that we have content such as:
Where {Bar} is user generated HTML that can contain arbitrary <H> tags.
I need a way to pick and choose.
Ideas?
For example:
The above index is, as far as I can tell, generated from <H1><H2><H3><...> tags.
The issue is that we have content such as:
<h1>Title</h1><h2>Chapter Foo</h2>{Bar}[...]
Where {Bar} is user generated HTML that can contain arbitrary <H> tags.
I need a way to pick and choose.
Ideas?