Formalising the Proximate Semantics of XML Languages with UML, OWL and GRDDL
- Henry S. Thompson, Language Technology Group, HCRC, School of Informatics, University of Edinburgh, World Wide Web Consortium, Markup Technology, Ltd., ht@inf.ed.ac.uk
Abstract
Many XML languages are defined in two steps, the first in terms of a mapping from XML documents to an abstract data model, the second by defining the meaning of the constituents of the abstract data model with respect to some domain. One obvious example is (X)HTML+CSS, where the first step is from document to nested boxes with properties, and the second is a set of claims that boxes+properties make on renderings. Another is W3C XML Schema, which explicitly separates the mapping from schema documents to schemas on the one hand from the schema-validation semantics of the schema components which make up schemas on the other.
This paper describes a novel approach to stating what it calls the proximate semantics of an XML language, that is, the mapping from XML information sets to language-specific (abstract) data models. The approach has three parts:
A set of conventions for constructing UML models, using the Violet open source graphical UML diagram editor;
A pipeline of XSLT stylesheets to convert the XML representation of those diagrams to OWL ontologies;
A set of guidelines for writing XSLT stylesheets or other transformations (e.g. pipelines) to implement GRDDL-triggered mapping from language documents to data model instances expressed in RDF.
The result of implementing this approach is that an OWL ontology for a language data model and an RDF instance corresponding to an individual language document can be combined and checked for consistency. The result, if consistent, can then also be compared to (RDF expressions of) concrete data model instances from an implementation. This would enable semi-automatic conformance testing, if the language specification actually included the three parts listed above.
Throughout the paper the points under discussion are illustrated with examples taken from the XML Processing Model language, currently under development by the W3C XML Processing Model Working Group. Some things were learned about that language while carrying out the exercise reported here, which are also briefly discussed.
Connections are also made to earlier work on expressing data-binding information via schema annotations, which suggest the possibility of auto-generating the stylesheets required for part (3) above in some cases.
Acknowledgements
Dan Connolly wrote the first Violet-to-OWL stylesheet, which really inspired this entire project.
Two-part, three-level definitions/implementations of (XML) languages
All but the simplest of formally defined languages are commonly understood, and usually defined, without going directly from notation to meaning. An intermediate level, more or less explicit, is appealed to, sometimes called 'abstract syntax' or 'underlying form' or 'abstract data model'. Concrete implementations of such languages often more-or-less directly reify this intermediate level in the data structures of the implementation substrate.
So both specifications and implementations often come in two parts: the mapping from notation to intermediate level, and the import (in principle or in practice) of the constituency of that level. This paper is concerned with the first part, primarily from the perspective of the producers and consumers of specifications.
The thesis set out in this paper is that specifications can and should include fully explicit, operational, definitions of both the intermediate level and the mapping. A particular set of technologies is proposed for accomplishing this when the language concerned uses XML for its notation.
The task naturally breaks down into two parts: defining the middle level (that is, the abstract data model), and mapping individual instances from XML to their middle-level form.
The middle level
The first part of our project requires us to produce an explicit, formal model of the middle level.
Defining the middle level
Nothing beats coloured pens and a whiteboard for designing object models, which is what this is really all about, but the step from there to XML is a bit under-supported at this point, so the next best thing is a drawing program. Not a general-purpose drawing program, but rather one intended for drawing object models. And one that outputs XML. And it should be free.
UML is one obvious candidate -- it's designed for graphical use, and there are free tools available for sketching simple UML diagrams easily. The one I found and have used for the work reported here is Violet [Horst05]. It's important to emphasise that I'm not really using UML in this exercise. Rather I'm using a UML drawing tool and a limited subset of the UML conventions for drawing object models:
The class hierarchy (with implied inheritance);
The property/attribute distinction;
Property cardinality and directionality annotations.
Each of these is illustrated in the following diagram for a very-much simplified subset of XProc [Wal07], the XML pipeline language currently under development by the W3C's XML Processing Model Working Group:
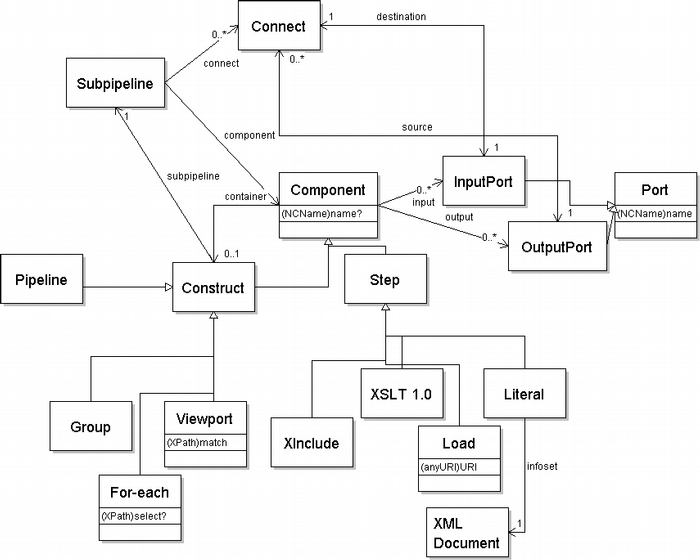
Figure 1. Simplified class diagram
Each box is a class, and arrows ending in open triangles indicate sub-class:super-class relations. So for example there are two kinds of Components, namely Steps and Constructs, and four kinds of Constructs, namely Pipelines, Groups, For-eaches and Viewports.
Attributes are given within class boxes, with types in parentheses and optionality indicated with a final '?'
Properties are notated with simple arrows. Cardinalities are given at the far end, so for example a Subpipeline has a connect property, which may be present zero or more times, and whose value is a Connect.
A double-headed arrow indicates a bi-directional property. For example a Connect has a single destination, which is an Input Port, and this relation is 1-to-1 and can be reversed, that is, an Input Port has a destination port as well, whose value is the Connect.
Violet uses Java's XML serialiser to dump its pictures, and the next step is accordingly to convert this format to something more congenial. I use a pipeline (!) of three XSLT steps to transform the Violet output into an OWL [OWL04] ontology. The figure below illustrates (selectively) how various aspects of the object model are translated:
<rdf:RDF xml:base="http://www.w3.org/2007/03/xproc">
[1] <owl:Class rdf:ID="Component">
<rdfs:subClassOf>
[5] <owl:Restriction>
<owl:onProperty rdf:resource="#name"/>
[7] <owl:maxCardinality
rdf:datatype="&xsd;#int">1</owl:cardinality>
</owl:Restriction>
</rdfs:subClassOf>
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#container"/>
[7] <owl:maxCardinality
rdf:datatype="&xsd;#integer">1</owl:maxCardinality>
</owl:Restriction>
</rdfs:subClassOf>
</owl:Class>
[2] <owl:DatatypeProperty rdf:ID="name">
<rdfs:domain> rdf:resource="#Component"/>
<rdfs:range rdf:resource="&xsd;.xsd#NCName"/>
</owl:DatatypeProperty>
[3] <owl:ObjectProperty rdf:ID="input">
<rdfs:domain> rdf:resource="#Component"/>
<rdfs:range rdf:resource="#InputPort"/>
</owl:ObjectProperty>
[3] <owl:ObjectProperty rdf:ID="container">
<rdfs:domain> rdf:resource="#Component"/>
<rdfs:range rdf:resource="#Construct"/>
</owl:ObjectProperty>
[1] <owl:Class rdf:ID="Construct">
[4] <rdfs:subClassOf rdf:resource="#Component"/>
<rdfs:subClassOf>
<owl:Restriction>
<owl:onProperty rdf:resource="#subpipeline"/>
[6] <owl:cardinality
rdf:datatype="&xsd;#int">1</owl:cardinality>
</owl:Restriction>
</rdfs:subClassOf>
</owl:Class>
<owl:ObjectProperty rdf:ID="subpipeline">
<rdfs:domain rdf:resource="#Construct"/>
<rdfs:range rdf:resource="#Subpipeline"/>
</owl:ObjectProperty>
</rdf:RDF>
All the key aspects of the OWL representation of the data model, as translated automatically from the quasi-UML diagram, are illustrated in this extract (the items below are keyed by number to the figure above):
Classes are . . . owl:Classes
Attributes are owl:DatatypePropertys
Properties are owl:ObjectPropertys
The class hierarchy is drawn using rdfs:subClassOf
Cardinality constraints are handled using subclassing and owl:Restriction
Required attrs/props have owl:cardinality restricted to 1 (see section ??? below for some discussion of this)
Optional attrs/props have owl:maxCardinality restricted to 1
Note that no cardinality constraints are present for e.g. the input property, as the UML range 0..* in the diagram means there is no constraint.
Working with the middle level
There are a number of free tools available for browsing and, to a limited extent, checking OWL ontologies. I've found SWOOP [SWOOP05], Protégé [Prot07] and Pellet [Pellet07] helpful in various ways (see also section ??? below). I also found it helpful to write a simplified version of the middle-level construction pipeline to simply extract and display all the properties from a Violet UML diagram, for example:
Table 1. Property listing from sample modelComponent | -- | | output | 0..* | --> | OutputPort |
Component | -- | | input | 0..* | --> | InputPort |
Component | -- | | container | 0..1 | --> | Construct |
Connect | <-- | 1 | destination | 1 | --> | InputPort |
Connect | <-- | 0..* | source | 1 | --> | OutputPort |
Construct | -- | | subpipeline | 1 | --> | Subpipeline |
Literal | -- | | infoset | 1 | --> | XML Document |
Subpipeline | -- | | component | 1..* | --> | Component |
Subpipeline | -- | | connect | 0..* | --> | Connect |
Developing the UML and inspecting and checking the corresponding OWL ontology interacted positively with the design process of the XProc language itself. When I couldn't determine exactly what to put in the model at certain points, I could sometimes identify under-specification in the language definition. I could then feed questions back to the Working Group to get the uncertainty resolved in a subsequent draft. I also was able to detect several places in which terminology was used in inconsistent or conflicting ways in different parts of the specification.
On the other hand, a simple class hierarchy with attributes and properties is a pretty modest modelling tool, and it is not surprising that not every difficulty in modelling represents a problem with the language being modelled. In particular, it is easy to state exceptions in the prose of a specification, but not always easy to capture them in a model. For example, the model, even in its simplified form, suggests that the 'container' property of Components is optional. If fact, it is obligatory for all components except the top-level pipeline. It would have been possible to express this in the model, but the resulting multiplication of classes would have been a very high price to pay in terms of perceived complexity.
The complete model in both Violet/UML and OWL, as well as the stylesheets needed to produce one from the other, are available online:
Violet to property display
Individual instances
The second part of our project requires us to integrate individual instances (documents in the language at hand) with the abstract data model, that is, to map from the XML notation of the language into appropriately decorated and connected instances of the classes in that model. Conformance to the language definition can be checked during the mapping process and at the end.
Mapping from XML (using GRDDL) -- Some design principles
The idea that the (in our case proximate) semantic content of an XML document can be mechanically derived from the document itself is the core proposition of the Gleaning Resource Descriptions from Dialects of Languages work [GRDDL07]. GRDDL provides conventions, both at the individual document level and at the level of namespaces or languages, for associating information about how to map from XML documents to their semantic content as notated using RDF. Although GRDDL singles out XSLT as the obvious means for expressing such mappings, it also mentions that pipelines of XSLT and other steps may be appropriate in complex cases, and we will indeed suggest that multiple steps are often appropriate.
"Divide and conquer" is an excellent software engineering design principle to use when confronted with what is, essentially, a compilation task. Breaking the overall transformation down into smaller steps not only facilitates debugging and maintenance, but also can shorten development time by facilitating understanding. In the particular case of the XProc language, the pipeline which effects the mapping, discussed briefly below, consists of six steps, all currently expressed using XSLT.
Two examples will suffice to illustrate the benefits of decomposing the mapping into stages:
The very first step in the pipeline operates solely on elements with attributes whose value is a QName. All it does is add two additional attributes in every such case, one with the local name and the other the namespace name, if any, resulting from looking up the appropriate namespace binding. This enables all the subsequent steps to operate on that pair of attributes, instead of having to reproduce the moderately complex testing, string surgery and lookup code whenever it was needed. This considerably improves readability.
XProc provides for quite a lot of defaulting of the connections between steps, by appeal to an environment which is recursively specified. The mapping process approaches this by constructing the environment in one step, and the connections in a subsequent step, appealing to the environment as necessary.
Another design principle which proved very useful was to organise the main mapping from the XML notation of pipeline steps into their RDF equivalents in terms of the class hierarchy itself. Named templates were defined for all but the lowest level of the class hierarchy, to carry out those aspects of the mapping which were appropriate to that level. Looking back at Figure ???, what this means is processing e.g. an p:for-each would involve not only a template which matches that element alone, but also a call to a named template for Constructs, and then in turn a call to a named template for Components.
The first, middle and last templates in this chain (and this would generalise to greater depth as needed) have a regular (and similar) structure:
<xsl:template match="[some element name]">
<correspondingClassName>
[add attributes as appropriate to this level alone]
<xsl:call-template name="[superClass]"/>
[add children as appropriate to this level alone]
</correspondingClassName>
</xsl:template>
<xsl:template name="[intermediate Class]">
[add attributes as appropriate to this level alone]
<xsl:call-template name="[superClass]"/>
[add children as appropriate to this level alone]
</xsl:template>
<xsl:template name="[top Class]">
[add attributes as appropriate to top level]
[add children as appropriate to top level]
</xsl:template>
So for instance in the p:for-each case, this would play out ore or less as follows:
<xsl:template match="p:for-each">
<For-each>
<xsl:call-template name="Construct"/>
<xsl:if test="@select"><select><xsl:value-of select="@select"/></select></xsl:if>
</For-each>
</xsl:template>
<xsl:template name="Construct">
<xsl:call-template name="Component"/>
<subpipeline>
<Subpipeline>...</Subpipeline>
</subpipeline>
</xsl:template>
<xsl:template name="Component">
<xsl:attribute name="rdf:about">...<xsl:value-of select="@name"/>...</xsl:attribute>
. . .
</xsl:template>
The standard pattern is reflected here. The element in the document itself determines the RDF class to create the instance, the Construct class template handles the subpipeline relation which is common to all constructs, and the Component class template gives the instance its RDF identity.
Checking
The mapping process provides the opportunity to check language constraints both using XSLT at the syntactic level for constraints which may not have been captured in a schema, and using ontology processors and/or SPARQL on the resulting RDF instance.
Checking the syntax with XSLT
For example, the XProc specification says: "It is a static error if the port specified by a p:pipe is not in the readable ports of the environment." This can be checked by the part of the mapping pipeline, mentioned above, which connects ports based on the contents of the environment, as computed by previous stages of the mapping.
Checking the RDF
Once a document has been mapped into RDF, the result, along with the ontology for the model whose construction was discussed in section ??? above, can be loaded into an ontology tool or 'reasoner' for consistency checking. For example, the Pellet 'reasoner' can detect maxCardinality violations (if it is instructed to treat all named individuals as distinct). This will detect multiple bindings to the same input port (if this has not been caught by schema or during mapping). During development, such a tool may also detect errors in the mapping itself.
The most common cardinality problem, particularly during model development, but also occurring with instances, is minCardinality failure, that is, the absence of some required property or attribute. It is in the nature of RDF/OWL that a 'reasoner' does not detect such errors, as they don't result in a contradiction -- one should understand a minCardinality assertion as saying "There is one, even if we haven't identified it yet." We can, however, detect missing information using a SPARQL [SPARQL06] query, as follows:
PREFIX owl: <http://www.w3.org/2002/07/owl#>
PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#>
SELECT ?x ?p
WHERE {
?r a owl:Restriction .
{ ?r owl:cardinality 1 } UNION { ?r owl:minCardinality 1 } .
?r owl:onProperty ?p .
?p rdfs:domain ?c .
?x a ?c .
OPTIONAL {?x ?p ?y}
FILTER (!bound(?y)) }
This can be read as saying "Find any relevant cardinality restrictions, then check all the instances of the domains of the restricted properties to see that they do indeed have a real value for that property."
Mapping stylesheets and example
The stylesheets for mapping from instances to models, along with an example based on Figure 1 of the XProc draft, are available:
Conclusions
Whether the availability of an easily inspected quasi-reference implementation of the first phase of implementing the XProc pipeline language will benefit implementers and users in the long run is impossible to say at this point. It is often remarked that early implementation aids specification, and that has certainly happened in this project. It has generated significant amounts of feedback into the specification process, in terms of questions, suggestions and observations.
Perhaps the most significant observation about the language which emerged from the model development work was that by far the easiest way to handle the duality of input and output ports on constructs such as Viewport (and Pipeline itself), was to recognise that despite their surface syntax, the things notated as p:input and p:output children of e.g. p:viewport were in fact instances of both InputPort and OutputPort.
Another potentially useful side-effect of the modelling effort was that it became necessary to introduce a new PipelineShell class, to hold the top-level pipeline and the contents of any imported libraries.
Finally, the very fact that a pipeline of stylesheets was by far the easiest way to specify the mappings involved is itself an encouraging comment on the importance of the XProc language. Although that particular benefit is unlikely to be relevant for efforts to specify other XML languages, I hope the other benefits of the particular instance of the "It's all just XML" philosophy illustrated by the methodology described here will be of just such wider relevance.
References
[GRDDL07] Connolly, D. ed. Gleaning Resource Descriptions from Dialects of Languages (GRDDL), W3C, 2007. Available online as http://www.w3.org/TR/grddl/.
[Pellet06] Sirin, E., B. Parsia et al. "Pellet: A practical OWL-DL reasoner", Journal of Web Semantics (To Appear), 2006 Available online at http://www.mindswap.org/papers/PelletJWS.pdf. Software download, documentation, etc. available online at http://pellet.owldl.com/.
[Horst05] Horstmann, C The Violet UML diagram editor, 2005. Documentation, demo app and download available online at http://www.horstmann.com/violet/.
[SWOOP06] Kalyanpur, A., B. Parsia, et al. "Swoop: A Web Ontology Editing Browser", Journal of Web Semantics, v. 4, n. 2, Science Direct, 2006. Available online at http://www.websemanticsjournal.org/ps/pub/2006-7. Software download etc. available at http://code.google.com/p/swoop/.
[OWL04] McGuinness, D and F. van Harmelen, eds. OWL Web Ontology Language Overview, W3C, 2004. Available online as http://www.w3.org/TR/owl-features/.
[Prot07] The Protégé ontology editor, Stanford University, 2007. Software download, documentation, etc. available online at http://protege.stanford.edu/.
[SPARQL06] Prud'hommeaux, E. and A. Seaborne eds. SPARQL Query Language for RDF, W3C, 2006. http://www.w3.org/TR/rdf-sparql-query/.
[Wal07] Walsh N. and A. Milowski, eds. XProc: An XML Pipeline Language, W3C, 2007. Available online as http://www.w3.org/TR/xproc/
{kind=link}